
○タイトルに惹かれて購入。実践知がつまった本。(1冊)
『 Real World Evaluation: Working under budget, time, data, and political constraints 』M.Bamberger & L.Mabry (2020) SAGE
●前書き J.Rugh(第1版 2006、第2版 2012の共著者)
・評価をできるだけ安く行う。
・実世界では、物事は単純ではない。
●PartI RWEの7ステップ
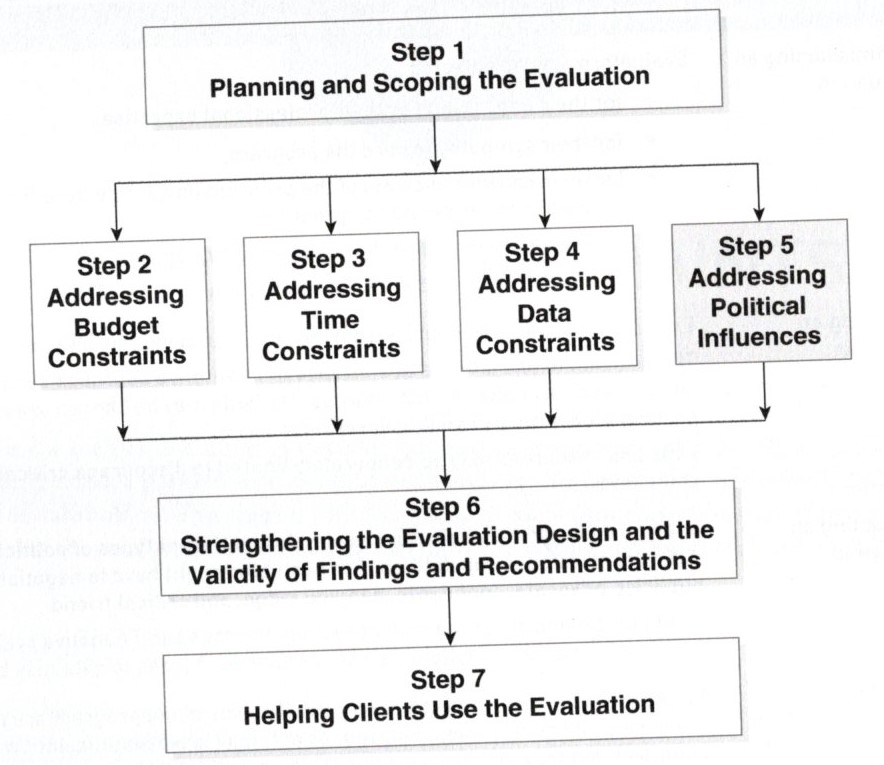
・4つの制約:予算、時間、データ、政治的影響
・Real World Evaluation(RWE)の7ステップ
・Value-free evaluationは、無い。
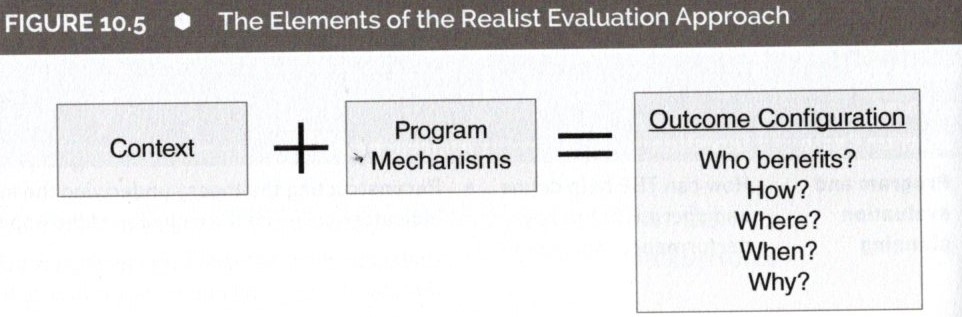
・Realist Evaluation(Pawson,2006他)では、次の質問を提案している。
1)誰がプログラムから便益を得るのか?
2)どのように便益を得るのか?
3)いつ便益を得るのか?
4)なぜ?
5)便益を得ないのは誰か?なぜ?
・鍵となるステークホルダーとは、なるべく早めにミーティングを行う。
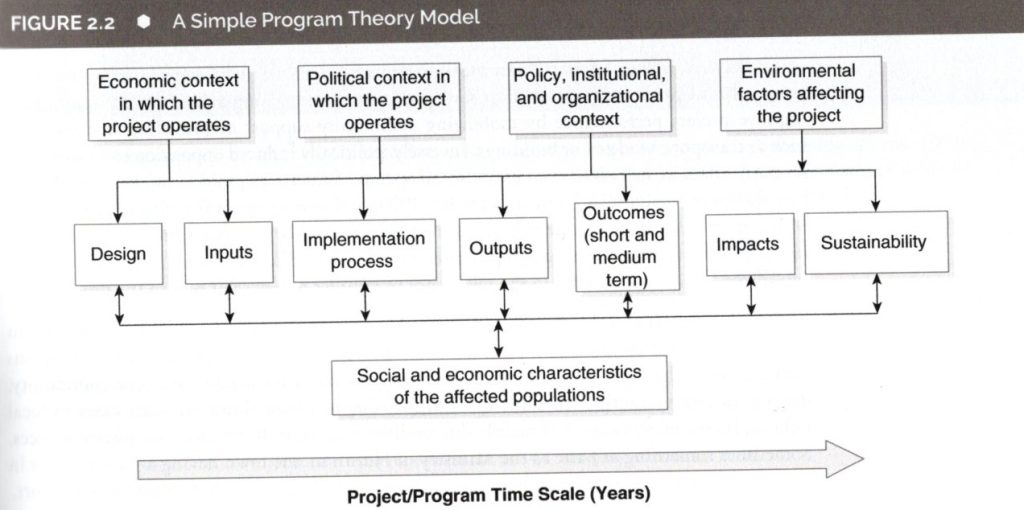
・アウトカムは、短期、中期の効果。インパクトは、長期の効果。
・誰が、評価を求めているのか?
・答えるべき質問は何か?
・評価は、形成的、総括的、発達的のどれか?
・予算が少ないなら、まずは、評価デザインを、シンプルにする。
・サンプル数、インタビュー者数、取得データを減らす。
・費用と時間を減らすことと、評価の質とValidity 妥当性とのトレードオフになる。
・時間がないと言われるときは、そもそも評価の重要度が低い場合が多い。
・時間を減らす時は、「期間」を短くするのか、「作業時間(労力)」を減らすのかを考える。
・Baseline data 基準データが無いことも多い。
・Retrospective survery 回顧、後ろ向き調査で、以前の状態を把握する。
・Comparison group 比較群が得られないことも多い。
・センシティブなテーマ(例:性、DV)や、アプローチしにくい集団(例:ギャング)もある。
○研修評価だと、こういう困難は殆どない。まだやりやすいんだろうな~。
・Values 価値と、Politics 政治は、切り離せない。
・「Clientism 顧客主義」 評価者は、顧客を喜ばせることを欲する(Scriven,1991)
・そのため、肯定的な結果のみ、顧客に提供し、葛藤を避けようとすることもある。
・(介入する)プログラムは、完ぺきではない。
・評価は、価値から離れることはできないし、完全に客観的になることもできない。
・評価は、人間の判断が関わる。
・評価デザインと結論の妥当性を強めていく。
・Random sampling、Peer review、Triangulation、Meta-evaluationを活用。
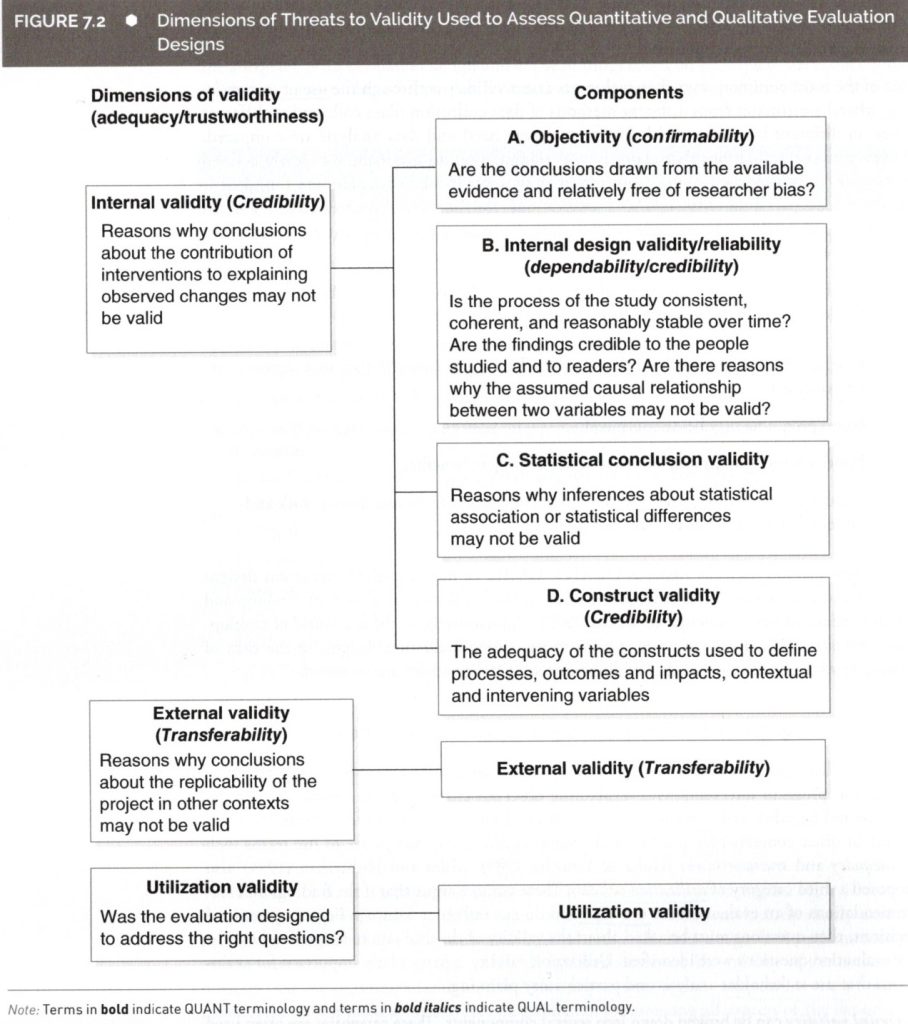
・妥当性の3種
1)Internal validity 内的妥当性
2)External validity 外的妥当性(Replicability)
3)Utilization validity 活用妥当性(評価結果が使われるかどうか)
・仮に、Methodology is weak 手法は弱いとしても、顧客が評価を、useful 使える!と考えることもある。
・否定的な結果や提言の場合、顧客が、反対し、評価結果を使わないこともある。
・Useful to whom? 誰にとって、使えるのか。
・評価結果の活用は、悲しいほど、低い(Patton 1997)
・評価結果のMisuse 間違った活用もある(House 1990)
・評価結果を活用してもらうために、顧客に評価プロセスに関与してもらい、「自分のものだ」という感覚を持ってもらう必要がある。
●PartII より深く学びたい人向け
・Standard and Ethics
・評価が、Awry 曲がる可能性を防ぐ
・The Program Evaluation Standard
1)Utility 2)Feasibility 3)Propriety 4)Accuracy 5)Accountability
・TBE:Theory Based Evaluation
・Theoryは、プログラムがどのように働くと考えられるかの仮説
・なぜ、どのように、期待される変化が起こると考えるのか。
・TOC:Theory of Change が、評価ではよくつかわれる。
・TOCは、評価期間中、見直しが図られるべきである。
・「Who」の重要性
・Ladder of Causality 因果のはしご
1)Association What if I do X?
2)Intervention What would happen to Y if I do X?
3)Counterfactual Was it X that caused Y?
・プロジェクト効果の3シナリオ
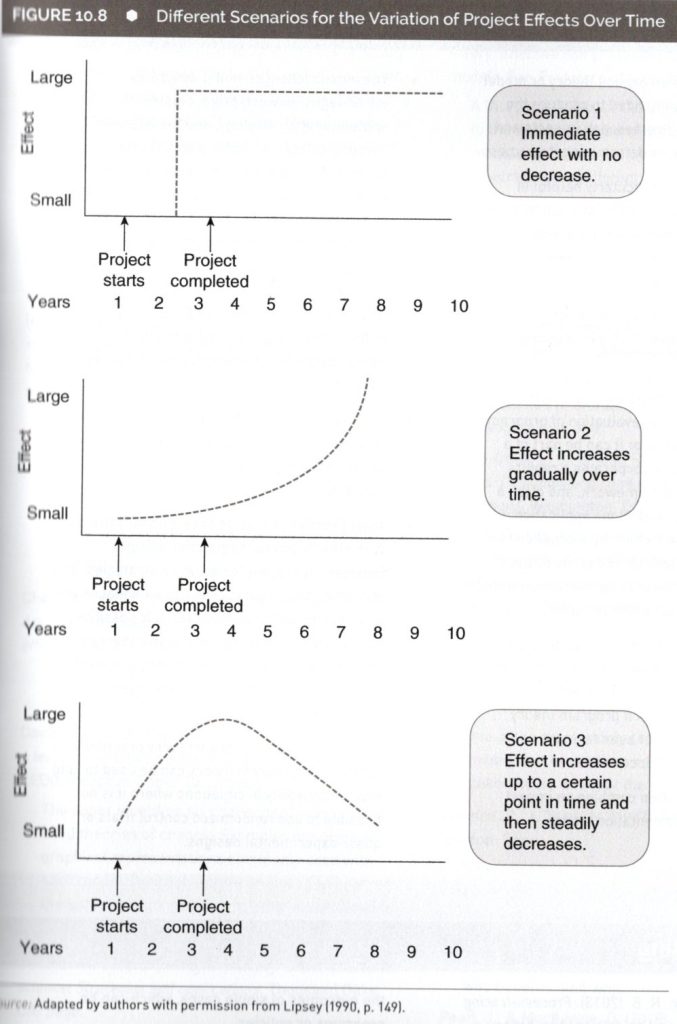
・評価では「Did the program work?」を見る。
・評価デザインの枠組みのいくつか
‐Longitudinal design
‐Pretest-posttest comparison group design
‐Posttest comparison group design
‐No comparison group design
・評価デザインは、大きく3つに分けられる
1)Experimental designs 実験デザイン
2)Quasi-experimental designs 準実験デザイン
3)Nonexperimental designs 非実験デザイン
・RCT:Randomized Control Trialは、Gold standardと言われるが、常に熱い議論に晒されている。
○やっぱり、人間(評価する側)が、人間(評価される側)に対して「実験する」っていうのが、きついんだろうな~。
・Qualitative methods定性手法は、評価の第四世代に含まれる(Guba&Lincoln,1989)
・観察、インタビュー
・定量と定性は、異なる哲学を基にしている。
・Incommensurability 通訳不可能性
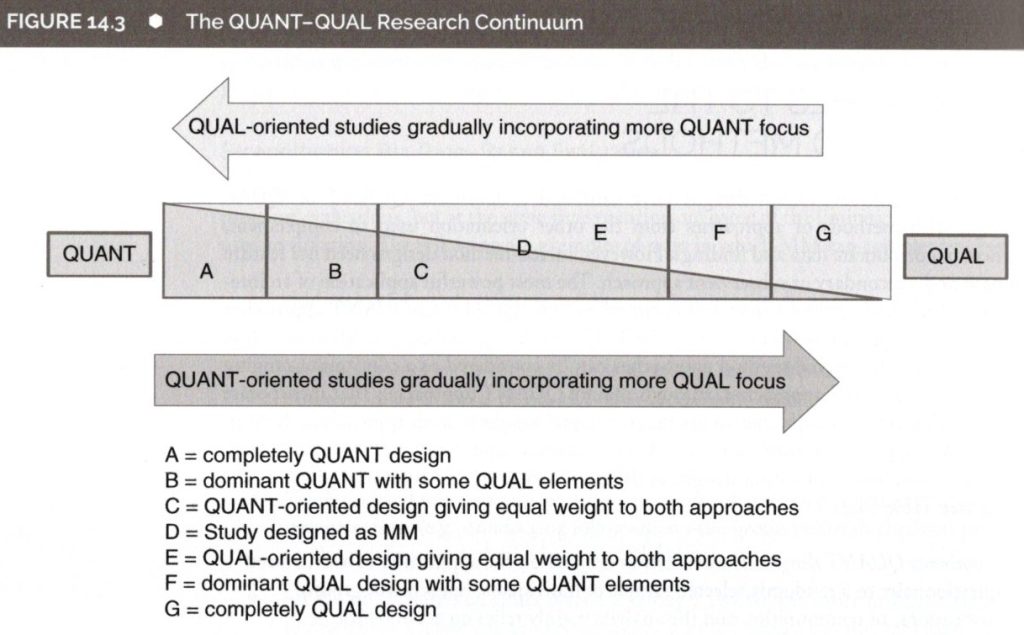
・Mixed Methodの使い方
1)順番 (定性→定量→定性)
2)同時 (定性&定量)
3)段階ごと
・定性では、Purposive sampling、定量では、Probability(Random)samplingが、使われる。
・t検定は、サンプルサイズが、30以下の場合、使われる。
・国際開発の世界では、複合し複雑化した介入が増えてきている。
・シンプルプロジェクト、複雑なプログラム、複雑な開発介入
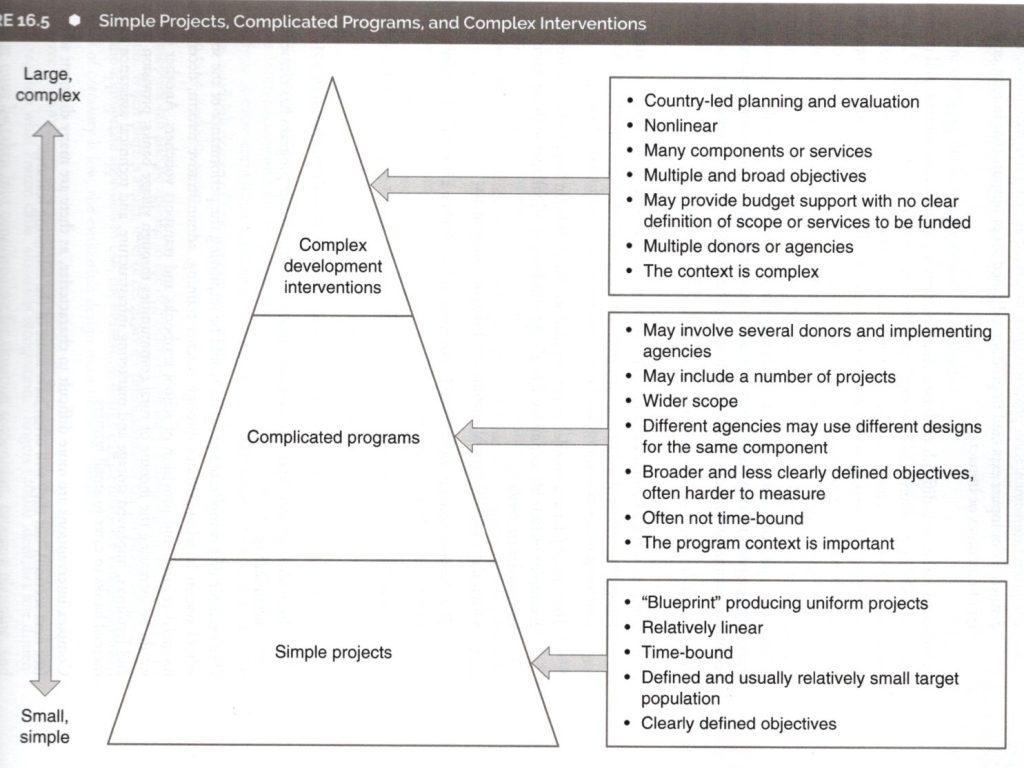
・複雑になればなるほど、評価が難しくなる。
・開発プログラムは、男女に対して、違う影響を与える。
・しかし、Gender neutralであるという前提に立つことが多い。
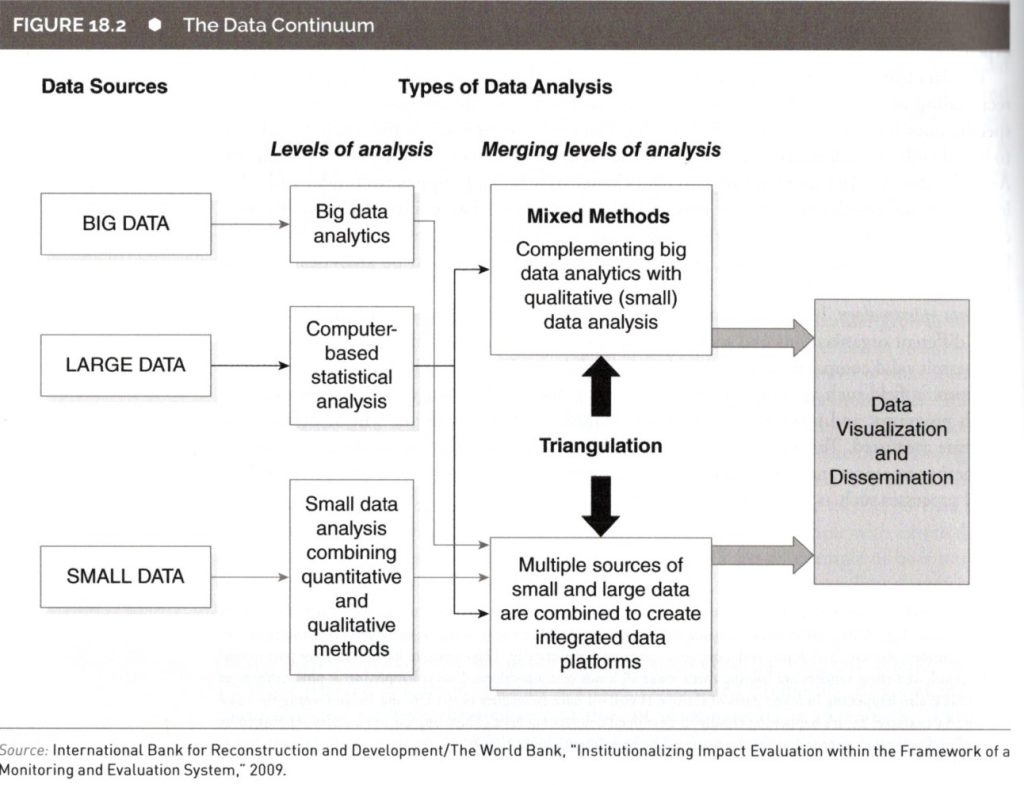
・Big data、Large data、Small dataと分けて考える。
●PartIII 評価の管理
・外部評価コンサルタントは、2種類に分けられる
1)評価実行者 2)評価技術サポート
・Statistically strong 統計的に強い評価と、Methodologically strong 手法的に強い評価がある。
・すべての評価デザインは、Question driven 質問中心であるべきで、Methods driven 手法中心であるべきではない。
・たった一つのベストな評価デザインは無い。
○読み終わった~! 立つぐらい分厚い本をよく読み切った!と自分をほめよう。

===
コメントフォーム